This page has been deprecated. The information contained here would not work.
Once you are able to generate large amount of data derivatives on brainlife.io, your next step might involve performing data aggregation for group or statistical analysis. You can download all data derivatives to your computer and conduct any post-processing on your own computer, however, downloading all derivatives might take a long time, and consume a lot of disk space. If you are wanting to quickly explore results of your analysis, this might not be ideal.
Brainlife allows Apps to generate condensed (textual) version of output data and store them on brailife.io database. Similar to data-object metadata, you can query and/or download this information without having to download the raw data derivatives. This data is called product.json. For example, "Tract Profile Analysis" App (https://brainlife.io/app/59ca5c03c27f5b0770add9cf){target=_blank} generates the following product.json.
The following code downloads data-object records from brainlife so that you can then iterate through each record and examine meta data, or product contents.
%define queryfind=struct;find.removed=false;find.project='5a74d1e26ed91402ce400cca';%project id from brainlife.iofind.datatype='5965467cb09297d8d81bdbcd';%tractprofile datatype (find in datatypes page)find.tags={'wNODDI','21600'};%you can filter by subjectfind.meta_dot_subject=struct('x_in',["103","105"]);%load brainlife access tokenjwt=fileread('~/.config/brainlife.io/.jwt');%use bl login to generate itoptions=weboptions()options.HeaderFields={'Authorization',['Bearer ',jwt]};options.Timeout=10;%could take a long time to load with a larger product..%load data-objectsdisp('Querying brainlife for data product...')disp(find)url='https://brainlife.io/api/warehouse/dataset';%I have to do some matlab > mongo query conversionfind_json=strrep(jsonencode(find),'x_','$');find_json=strrep(find_json,'_dot_','.');data=webread(url,'find',find_json,'select','product','limit','1000',options);%TODO ... do things with data.datasetsdisp('loaded! - enjoy with data')disp(data)
Similarly, you can query data-object records using python.
1 2 3 4 5 6 7 8 910111213141516171819202122
#!/usr/bin/pythonimportrequestsimportosimportjson#load the jwt token (run bl login to create this file)jwt_file=open(os.environ['HOME']+'/.config/brainlife.io/.jwt',mode='r')jwt=jwt_file.read()#query datasets recordsfind={'datatype':'58c33bcee13a50849b25879a','project':'5cb8973c71a8630036207a6a','tags':'acpc_aligned'}params={'limit':100,'select':'product meta',#we just want product and meta'find':json.JSONEncoder().encode(find)}res=requests.get('https://brainlife.io/api/warehouse/dataset/',params=params,headers={'Authorization':'Bearer '+jwt})ifres.status_code!=200:raiseError("failed to download datasets list")
As you can see, you can construct your query and make a request to brainlife API with your access token issued by running bl login. Once you obtain the dataset records (res) you can iterate through each dataset and do any group analysis, or generate visualization using the content of meta and product objects.
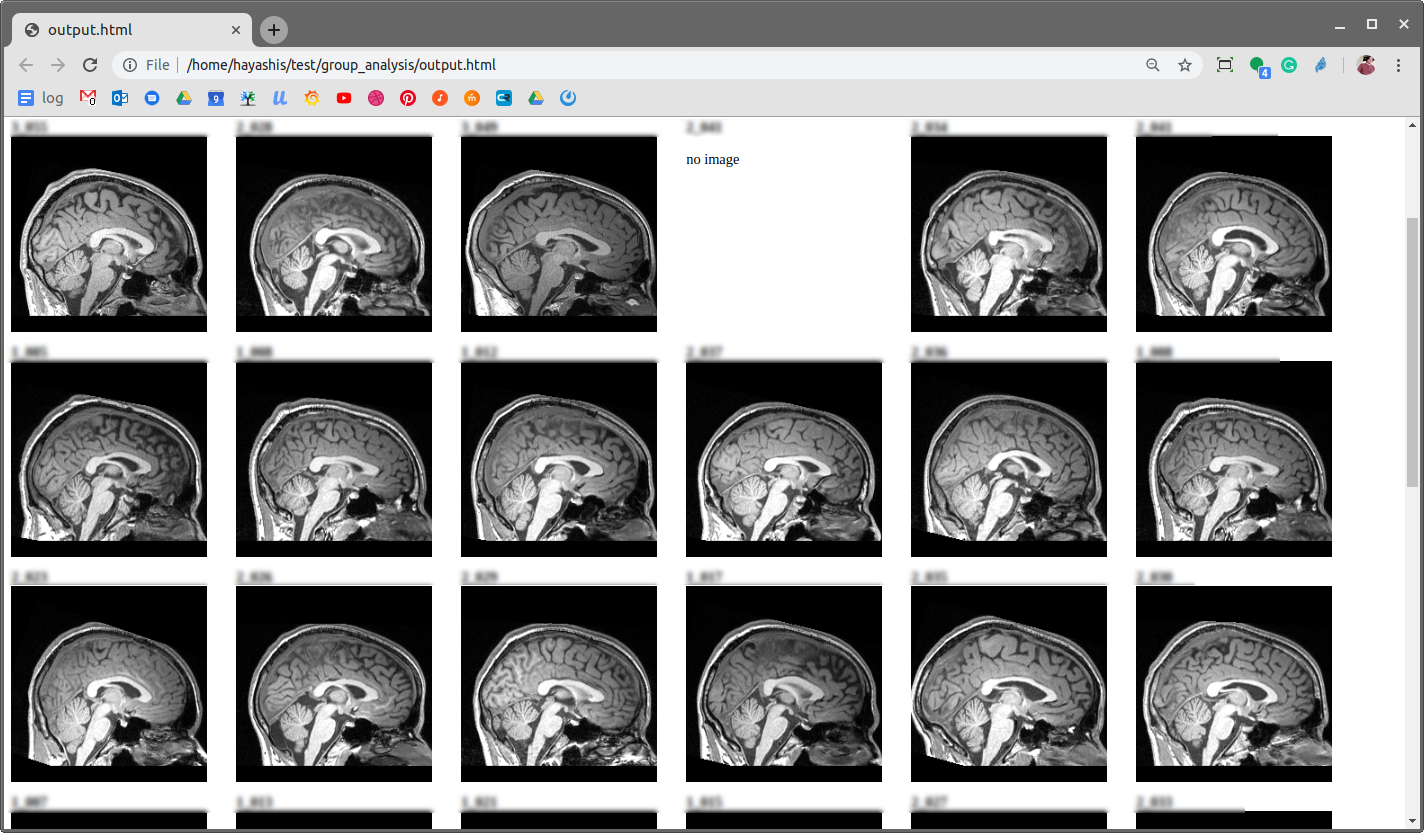
For example, the following code shows how to convert the QC images from ACPC Alignment App into a single HTML page.
#load product.json for each datasetdata=res.json()fordatasetindata["datasets"]:id=dataset["_id"]subject=dataset["meta"]["subject"]print('<div style="float: left; height: 250px; width: 250px;">');print("<b>"+subject+"</b><br>")res=requests.get('https://brainlife.io/api/warehouse/dataset/product/'+dataset["_id"],headers={'Authorization':'Bearer '+jwt})ifres.status_code!=200:raiseError("failed to download product.json")data=res.json()product=data["product"]image64=None#output image if it has oneif"brainlife"inproduct:brainlife=product["brainlife"]iflen(brainlife)==1:brainlife0=brainlife[0]if"base64"inbrainlife0:image64=brainlife0["base64"]ifimage64:print('<img src="data:image/png;base64,'+image64+'">\n')else:print('<p>no image</p>\n')print('</div>')
You can run this script and capture the output to generate HTML file. You can then open it with your browser.